
Positional Embeddings in LLMs
How positional embeddings give meaning to word order in LLMs


Today, we are going to understand positional embeddings and why they are essential for Large Language Models.
I’m Amit Shekhar from Outcome School, where I teach AI and Machine Learning, and Android.
Let’s get started.
Large Language Models do NOT have any notion of the order of words, because they process tokens in parallel, not sequentially like RNNs.
To inject information about the position of each token in the sequence, positional embeddings are added.
So, it helps in providing the information about the position of the word to the model.
For example: Outcome School
If we do not provide positional information, the model has no way of knowing whether it is "Outcome School" or "School Outcome".
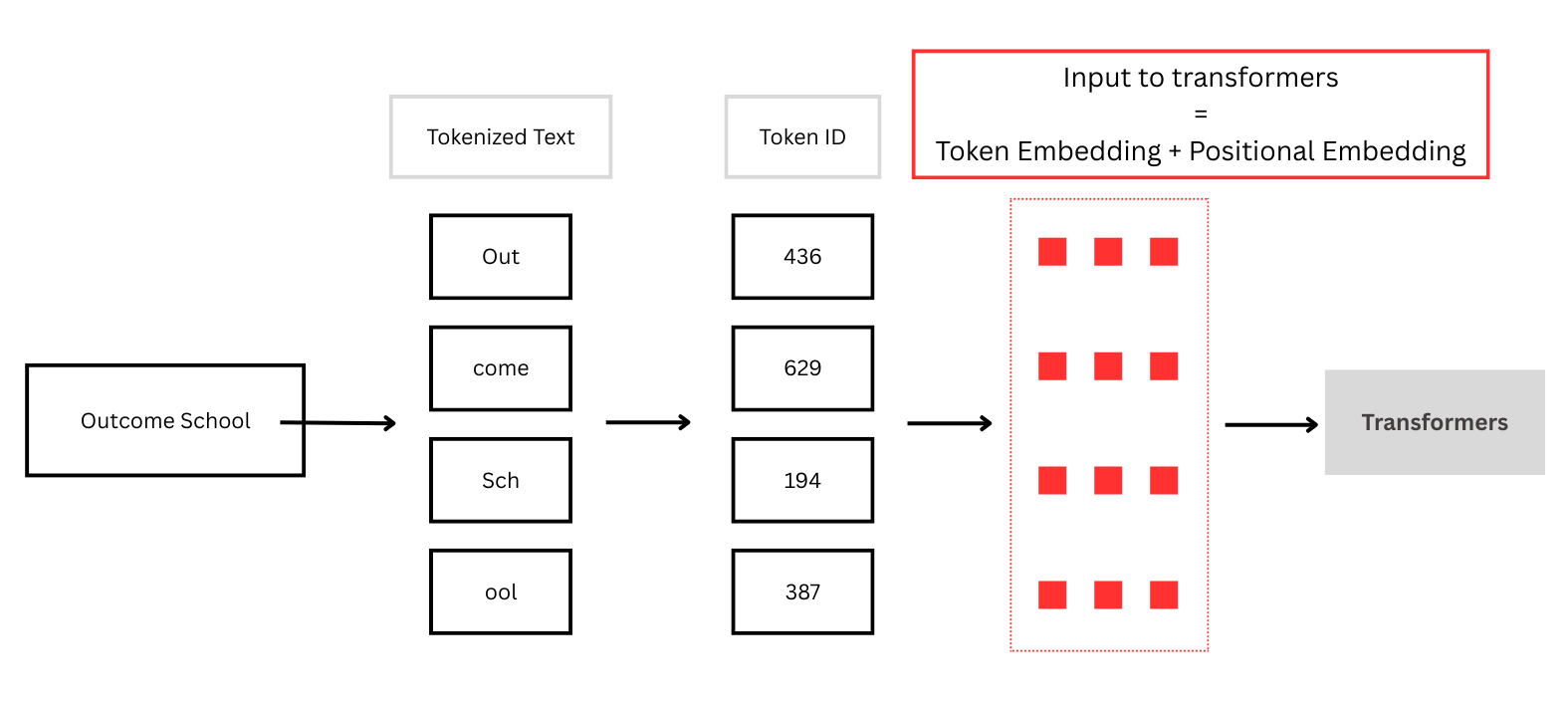
So, before feeding the input into the transformers, we need to do the following:
Tokenization: Converting raw text into smaller units (tokens) and mapping them to numbers that the model can understand and process.
Token Embedding + Positional Embedding
So, the Positional Embedding helps in providing the information about the position of the word to the model.
I teach these types of concepts at Outcome School and help you become a better software engineer.
Thanks
Amit Shekhar
Founder, Outcome School
Positional embeddings inject word order information into Transformers by encoding each word’s position and combining it with its word embedding, allowing the model to understand sequence structure and meaning