
Quantization in LLMs
Trading numerical precision for efficiency.


I’m Amit Shekhar from Outcome School, where I teach AI and Machine Learning.
Let’s get started.
What is Quantization?
Running large AI models on smaller hardware by trading numerical precision for efficiency.
An LLM is just a file full of numbers
Every LLM is essentially a large file containing billions of weights. These weights are the numbers the model learned during training. They define how the model thinks.
Each weight is stored with a precision
By default, each weight is a 32-bit floating point number - highly precise, but expensive in memory. A 7B model has 7 billion of these. That adds up to ~28 GB just to load it.
Quantization reduces that precision
Instead of storing a float like 1.9182736 with 7 significant digits (FP32), quantization reduces that to just 3-4 significant digits (FP16) like 1.918. The model gets smaller and faster - with only a small drop in quality.

FP32 ~7 significant digits 1.9182736 float - full precision
FP16 ~3–4 significant digits 1.918 float - half precision
If you want to learn everything about the LLM, RAG, MCP, Agent, Fine-tuning, and Quantization, refer to the AI Engineering Explained: LLM, RAG, MCP, Agent, Fine-Tuning, Quantization.

For a quick reference on model sizes, FP32 vs FP16:
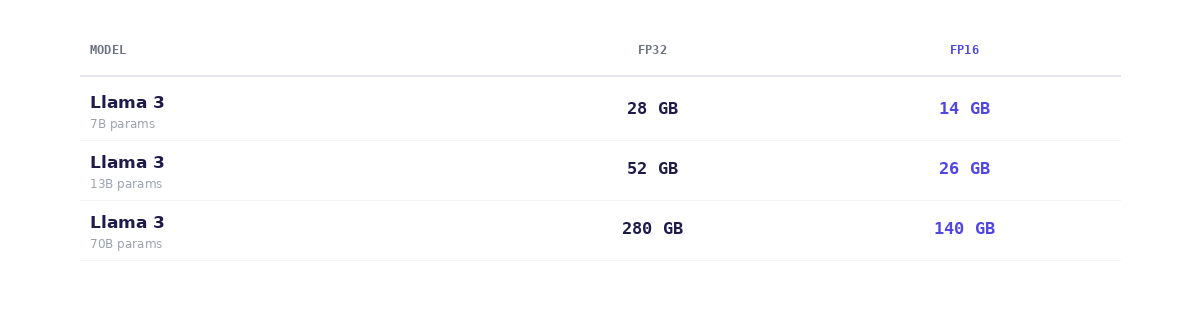
Each weight in an LLM is a floating point number stored with a certain precision. So with quantization, we are cutting memory in half with minimal quality loss. This is the most common quantization step used in production LLM inference today.
Thanks
Amit Shekhar
Founder, Outcome School