
Tokenization in Large Language Models (LLMs)
How text is converted into numbers that LLMs understand.


Today, we are going to understand Tokenization and why they are essential for Large Language Models.
I’m Amit Shekhar from Outcome School, where I teach AI and Machine Learning, and Android.
Let’s get started.
Large Language Models do NOT read words, they read tokens represented as numerical IDs. So, we need to create tokens and provide numerical IDs to them.
Tokenization is the process of breaking down text into smaller units called tokens, which can be words, subwords, or characters.
Example: “Outcome School”
A token is a piece of text: it could be anything like:
[Words] Word tokenization: “outcome”, “school”
[Subwords] Byte Pair Encoding (BPE): “out”, “come”, “sch”, “ool”
[Characters] Character-level: “o”, “u”, “t”, “c”, “o”, “m”, “e”
Each token is then mapped to a unique numerical ID that the model uses for computation.
Input: “Outcome School”
Tokens: [“out”, “come”, “sch”, “ool”]
Token IDs: [436, 629, 194, 387] (integer is coming from the defined map, out: 436, come: 629, and so on)
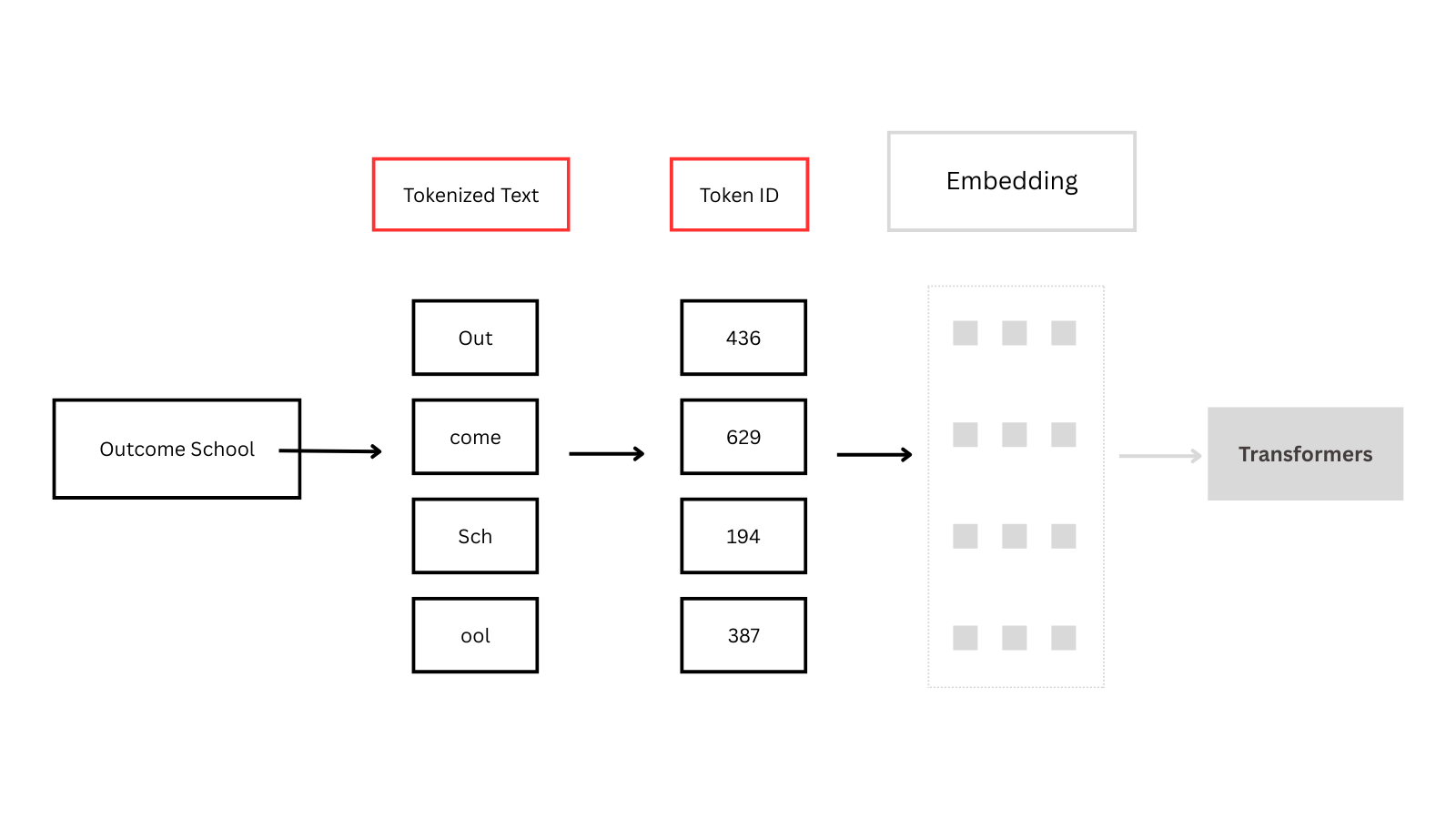
As the model can only process numerical data, not raw text, tokenization helps us achieve that.
I will share more in an upcoming post about how to choose between word, subword, and character-level tokenization, and how each choice affects model performance.
I teach these types of concepts at Outcome School and help you become a better software engineer.
Thanks
Amit Shekhar
Founder, Outcome School